Metric calculations
The metric calculations methods can be grouped into two categories as follows.
Area and Percent
For metrics that use area and percent, the calculations are straightforward. Using GIS, we determined the area of overlap and the percent of the parcel area. For example, for the forest metric, we determined how much forest area overlapped with each parcel and what the percentage of the parcel.
Distance
A number of metrics require a distance calculation, for example, distance of a parcel from a waterbody or wetland. This may sound simple and it is when it is point to point. It is more complicated when the distance is between two polygons (a polygon is a shape with area) and distance can be calculated from the closest corner, the center, or somewhere else. To further add to the complication, the calculation needed to measure the distance from features within the watershed ONLY, even if a feature in another watershed was closer.
To illustrate, see the graphic below. The blue lines are basin boundaries. The small parcel, highlighted in cyan, is closer to the eastern waterbody (orange arrow) than the western waterbody (red arrow). In a standard GIS calculation, the distance to the eastern waterbody would be recorded as the shortest distance but this doesn’t make sense as it is part of a different watershed. The method used in the project calculates the distance from the parcel to the nearest waterbody in the SAME WATERSHED (the distance shown by the red arrow).
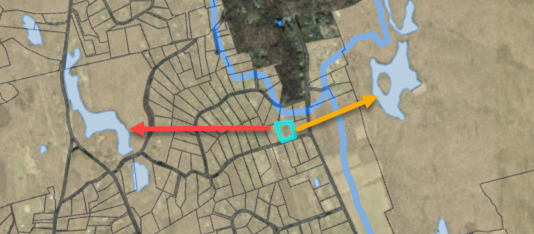
Example of distance calculation from a polygon to waterbody, where the red arrow is the correct distance because it is within the watershed, even though the orange area distance is shorter.
Metric weighting
The metric weights determine how much influence an individual metric has on the final parcel rank. Metrics with higher weights are deemed more important by the project team.
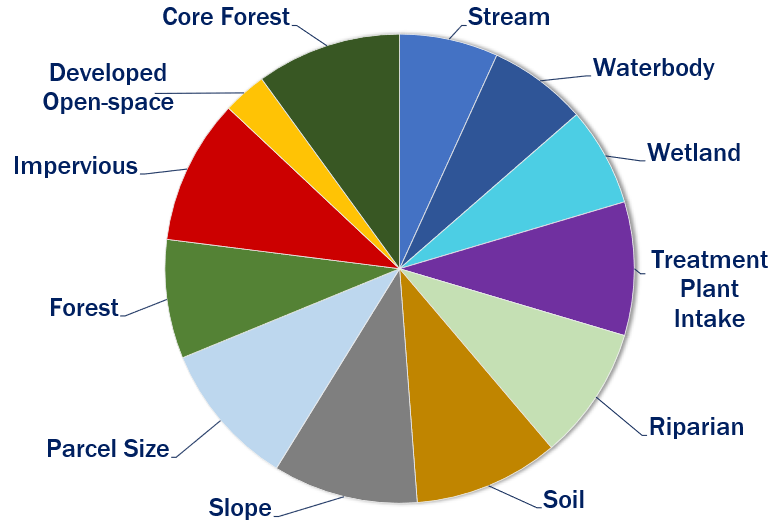
Surface Water Metric Weights
| Metric | Weight |
| Distance to streams | 0.068 |
| Distance to waterbodies | 0.068 |
| Distance to wetlands | 0.092 |
| Distance to treatment buffer intake | 0.092 |
| Contains stream bank/riparian | 0.092 |
| Soils | 0.100 |
| Slope | 0.100 |
| Parcel Size | 0.100 |
| Forest Cover | 0.082 |
| Impervious Surface | 0.100 |
| Developed Open Space | 0.030 |
| Core Forest | 0.100 |
| TOTAL | 1.000 |
A pie chart helps visualize the metric weights shown in the table. The larger the slice of pie, the more contribution to the rank.
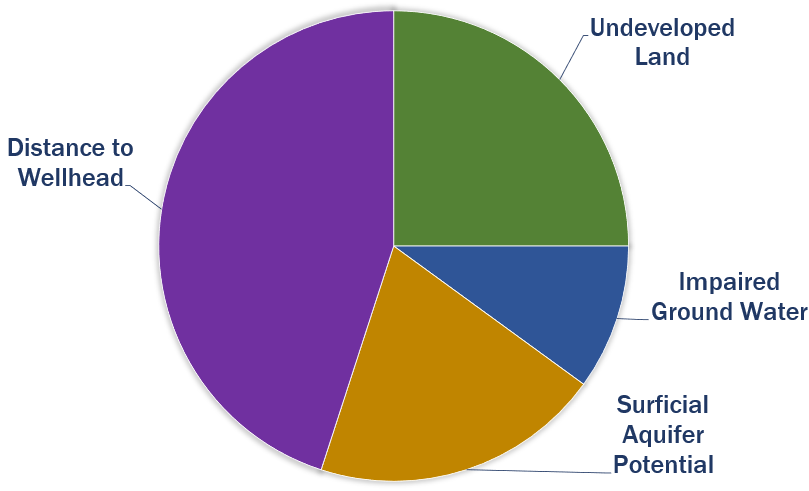
Ground Water Metric Weights
| Metric | Weight |
| Undeveloped land | 0.250 |
| Ground water quality | 0.100 |
| Surficial aquifer potential | 0.200 |
| Distance to wellhead buffer | 0.450 |
| TOTAL | 1.000 |
A pie chart helps visualize the metric weights shown in the table. The larger the slice of pie, the more contribution to the rank.
Sub-Metrics
Some metrics are made up of more than one metric, called a sub-metric. For example, the Distance to Waterbodies metric consists of BOTH (1) distance to waterbody and (2) percent of parcel that contains waterbody. Sub-metrics each contribute a piece to the full metric weight. In most cases when two sub-metrics are involved, the contribution is equal, or 50%. One exception is the Distance to Treatment Buffer metric where the sub-metric distance to intake buffer contributes 70% while the distance to intake reservoir contributes 30%. Another exception is the Slope metric where the area with extremely steep slope contributes 75% and the area of moderately steep slope contributes 25%. The final exception is the Soils metric which is made of four sub-metrics, each of which contributes 25%.
Only one ground water metric, Undeveloped Land, consists of two sub-metrics and they are not divided equally. The area of parcel that is undeveloped contributes 70% and the percent of parcel that is undeveloped contributes 30%.
TIP! The sub-metric contribution values are included in the metric descriptions for both source water metrics and ground water metrics.
Example
As described above, the Distance to Treatment Buffer metric has a metric weight of 0.092 and includes two sub-metrics.
Sub-metric 1: distance to intake buffer, contributes 70% to metric weight.
Sub-metric 2: distance to intake reservoir, contributes 30% to metric weight.
Formula: Weight of sub-metric = metric weight x sub-metric contribution
Weight of Sub-metric 1 = 0.092 x 70% = 0.0644
Weight of Sub-metric 2 = 0.092 x 30% = 0.0276
Parcel Ranking
Parcel rank for a given parcel is calculated by summing the multiplication between a metric weight and its metric score for all the metrics. See the Metric weighting section for more on how the contributing weights are determined.
Rank = ∑ Weights x Metric Score
Since metric weights add to 1 and metric scores range from 0 to 10, parcel ranks range from 0 to 10. The higher the rank (close to 10), the more desirable the parcel.
Example
As described in the Metric weighting section, the Distance to Treatment Buffer metric has two sub-metrics: 1) sub-metric 1 (distance to intake buffer) with a weight of 0.0644, and 2) sub-metric 2 (distance to intake reservoir) with a weight of 0.0276. The categories and scores for these two sub-metrics are the same and shown in the table.
| Category | Score |
| 0 - 15 feet | 10 |
| 15 - 300 feet | 6.67 |
| 300 - 500 feet | 3.33 |
| > 500 feet | 0 |
An example parcel has a score of 10 for sub-metric 1 and a score of 6.67 for sub-metric 2. The rank of this parcel for the Distance to Treatment Buffer metric is calculated as
Rank of Sub-metric 1 = 0.0644 x 10 = 0.644
Rank of Sub-metric 2 = 0.0276 x 6.67 = 0.184
Rank contribution of the Distance to Treatment Buffer metric = 0.644 + 0.184 = 0.828
We repeat this calculation for all metrics and then sum up the rank contributions to derive the final rank for this parcel.
Scaled Rank
Because no parcel reached the total possible surface water rank of 10, the results were stretched, or scaled, to fill the full range of 0-10. This further separated parcel ranks making them easier to explore and better highlighted the most desirable parcels with high ranks. To be fully transparent, BOTH the actual rank and scaled rank are reported on the Parcel Information Panel (left side) of the Parcel Prioritization Viewer.

In this example, the ranking math resulted in a 7.23 out of 10. When the values were stretched so that the highest actual parcel rank is 10, this parcel receives a surface water rank of 8.8. The map layers and Parcel Priority Dashboard use the scaled rank throughout.
Repeatability through GIS tools
We recognize that this analysis is a point in time. Data layers will improve, including the base parcels, and the analysis will need an update. Each step of the analysis was created as a tool within a toolbox in ArcGIS Pro. The tools are grouped based on the metric. The tools also allow for data and data layer updates and enable the methods to be applied to other regions that may have different input datasets.

If you are interested in the tools, please contact us at clear@uconn.edu and mention the Source Water project GIS toolbox.
Support for this project was provided by the Connecticut Council on Soil and Water Conservation, in partnership with the Connecticut Department of Public Health.
![]()
![]()